渲染,提交与挂载(渲染流水线)
This document refers to the architecture of the new renderer, Fabric, that is in active roll-out.
React Native 渲染器通过一系列加工处理,将 React 代码渲染到宿主平台。这一系列加工处理就是渲染流水线�(pipeline),它的作用是初始化渲染和 UI 状态更新。 接下来介绍的是渲染流水线,及其在各种场景中的不同之处。
(译注:pipeline 的原义是将计算机指令处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快指令执行速度。其具体执行过程类似工厂中的流水线,并因此得名。)
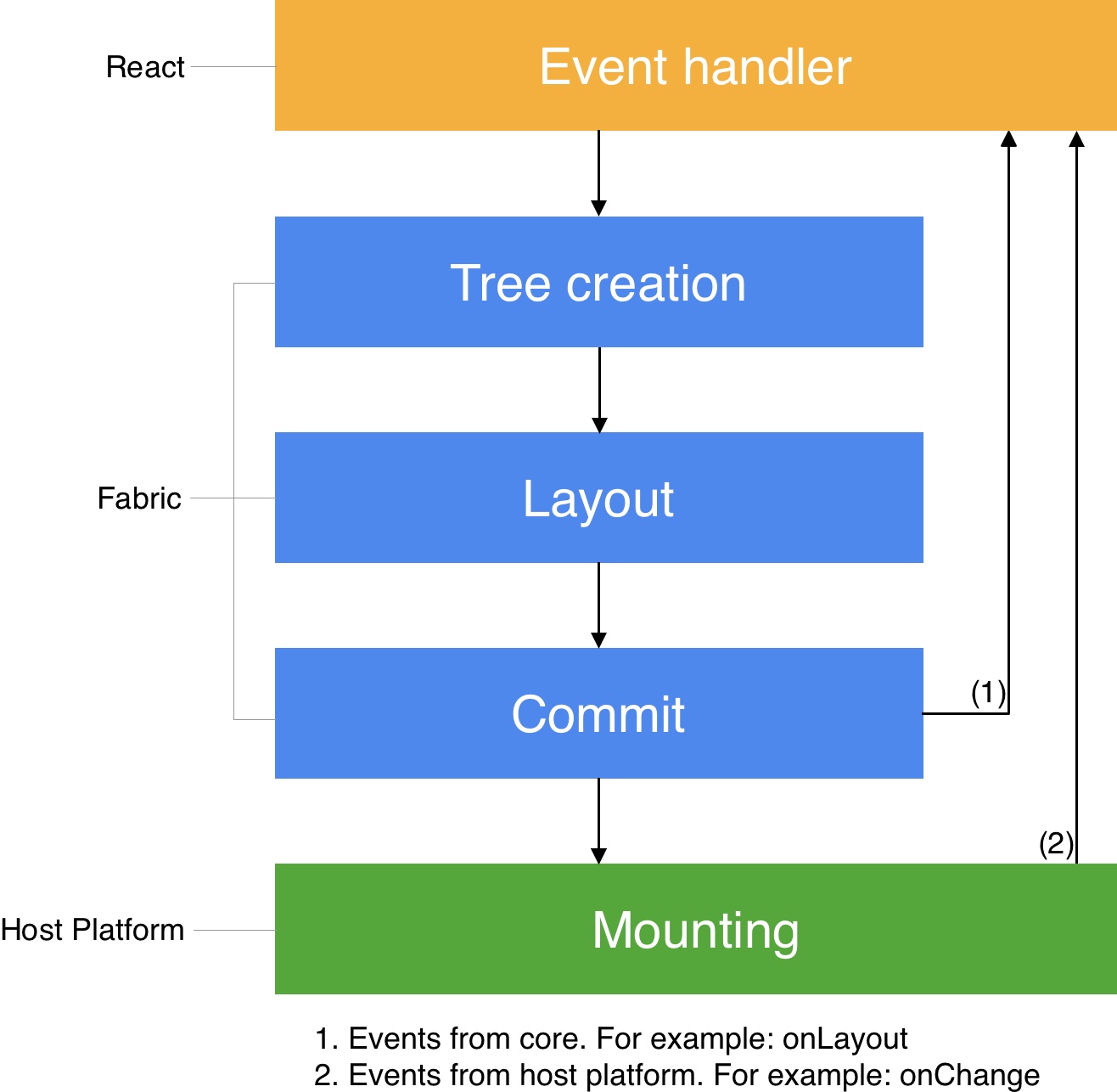
渲染流水线可大致分为三个阶段:
- 渲染(Render):在 JavaScript 中,React 执行那些产品逻辑代码创建 React 元素树(React Element Trees)。然后在 C++ 中,用 React 元素树创建 React 影子树(React Shadow Tree)。
- 提交(Commit):在 React 影子树完全创建后,渲染器会触发一次提交。这会将 React 元素树和新创建的 React 影子树的提升为“下一棵要挂载的树”。 这个过程中也包括了布局信息计算。
- 挂载(Mount):React 影子树有了布局计算结果后,它会被转化为一个宿主视图树(Host View Tree)。
渲染流水线的各个阶段可能发生在不同的线程中,更详细的信息可以参考线程模型部分。
渲染流水线存在三种不同场景:
- 初始化渲染
- React 状态更新
- React Native 渲染器的状态更新
初次渲染
想象一下你准备渲染一个组件:
function MyComponent() {
return (
<View>
<Text>Hello, World</Text>
</View>
);
}
// <MyComponent />
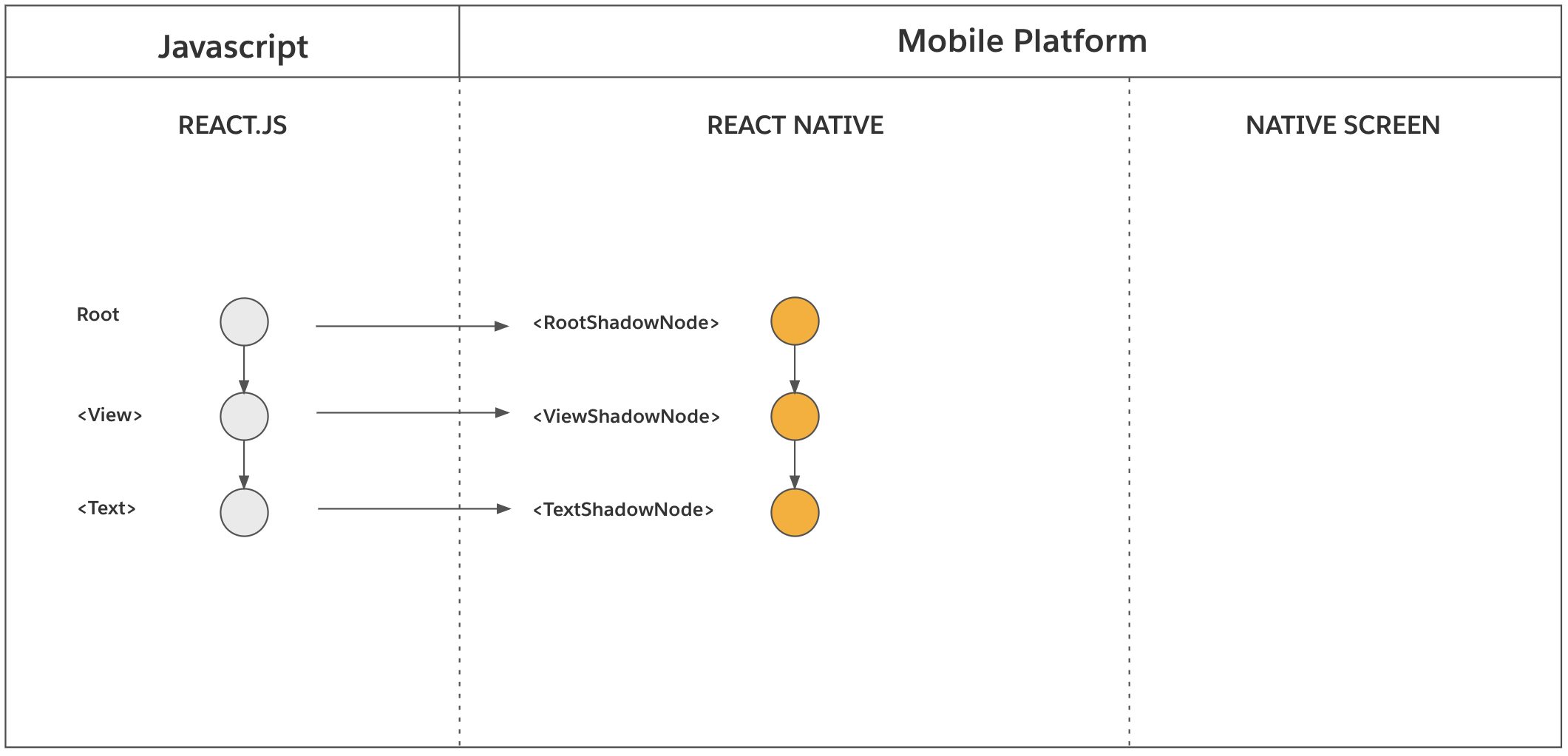
在上面的例子中, <MyComponent />是 React 元素。React 会将 React 元素简化为最终的 React 宿主组件。每一次都会递归地调用函数组件 MyComponet ,或类组件的 render 方法,直至所有的组件都被调用过。现在,你拥有一棵 React 宿主组件的 React 元素树。
阶段��一:渲染

在元素简化的过程中,每调用一个 React 元素,渲染器同时会同步地创建 React 影子节点。这个过程只发生在 React 宿主组件上,不会发生在 React 复合组件上。比如,一个 <View>会创建一个 ViewShadowNode 对象,一个<Text>会创建一个TextShadowNode对象。注意,<MyComponent>并没有直接对应的 React 影子节点。
在 React 为两个 React 元素节点创建一对父子关系的同时,渲染器也会为对应的 React 影子节点创建一样的父子关系。这就是影子节点的组装方式。
其他细节
- 创建 React 影子节点、创建两个影子节点的父子关系的操作是同步的,也是线程安全的。该操作的执行是从 React(JavaScript)到渲染器(C++)的,大部分情况下是在 JavaScript 线程上执行的。(译注:后面线程模型有解释)
- React 元素树和元素树中的元素并不是一直存在的,它只一个当前视图的描述,而最终是由 React “fiber” 来实现的。每一个 “fiber” 都代表一个宿主组件,存着一个 C++ 指针,指向 React 影子节点。这些都是因为有了 JSI 才有可能实现的。学习更多关于 “fibers” 的资料参考这篇文档。
- React 影子树是不可变的。为了更新任意的 React 影子节点,渲染器会创建了一棵新的 React 影子树。为了让状态更新更高效,渲染器提供了 clone 操作。更多细节可参考后��面的 React 状态更新部分。
在上面的示例中,各个渲染阶段的产物如图所示:
在 React 影子树创建完成后,渲染器触发了一次 React 元素树的提交。
阶段二:提交

提交阶段(Commit Phase)由两个操作组成:布局计算和树的提升。
- 布局计算(Layout Calculation):这一步会计算每个 React 影子节点的位置和大小。在 React Native 中,每一个 React 影子节点的布局都是通过 Yoga 布局引擎来计算的。实际的计算需要考虑每一个 React 影子节点的样式,该样式来自于 JavaScript 中的 React 元素。计算还需要考虑 React 影子树的根节点的布局约束,这决定了最终节点能够拥有多少可用空间。
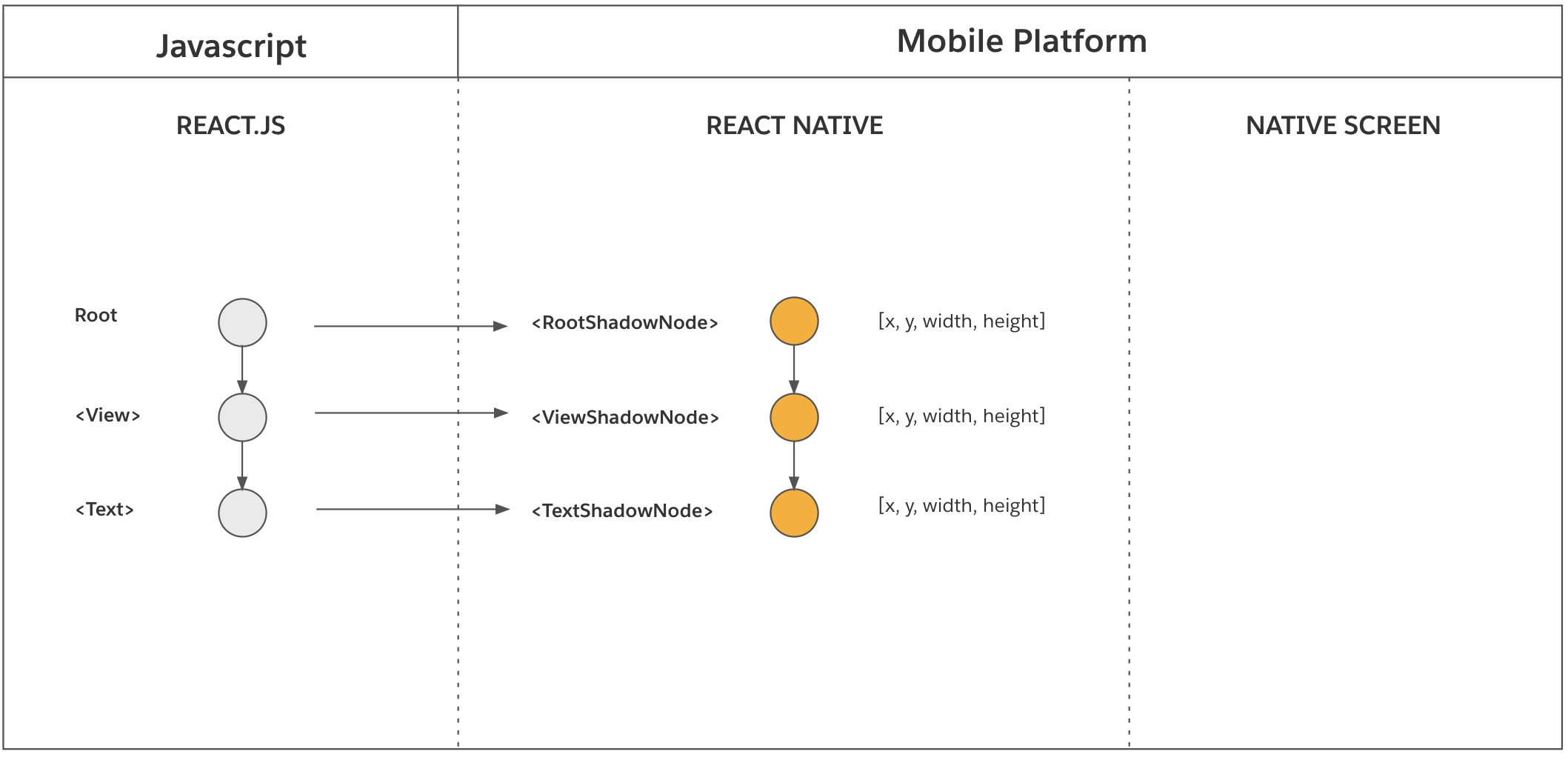
- 树提升,从新树到下一棵树(Tree Promotion,New Tree → Next Tree):这一步会将新的 React 影子树提升为要挂载的下一棵树。这次提升代表着新树拥有了所有要挂载的信息,并且能够代表 React 元素树的最新状态。下一棵树会在 UI 线程下一个“tick”进行挂载。(译注:tick 是 CPU 的最小时间单元)
更多细节
- 这些操作都是在后台线程中异步执行的。
- 绝大多数布局计算都是 C++ 中执行,只有某些组件,比如 Text、TextInput 组件等等,的布局计算是在宿主平台执行的。文字的大小和位置在每个宿主平台都是特别的,需要在宿主平台层进行计算。为此,Yoga 布局引擎调用了宿主平台的函数来计算这些组件的布局。
阶段三:挂载

挂载阶段(Mount Phase)会将已经包含布局计算数据的 React 影子树,转换为以像素形式渲染在屏幕中的宿主视图树。请记住,这棵 React 元素树看起来是这样的:
<View>
<Text>Hello, World</Text>
</View>
站在更高的抽象层次上,React Native 渲染器为每个 React 影子节点创建了对应的宿主视图,并且将它们挂载在屏幕上。在上面的例子中,渲染器为<View> 创建了android.view.ViewGroup 实例,为 <Text> 创建了文字内容为“Hello World”的 android.widget.TextView实例 。iOS 也是类似的,创建了一个 UIView 并调用 NSLayoutManager 创建文本。然后会为宿主视图配置来自 React 影子节点上的属性,这些宿主视图的大小位置都是通过计算好的布局信息配置的。
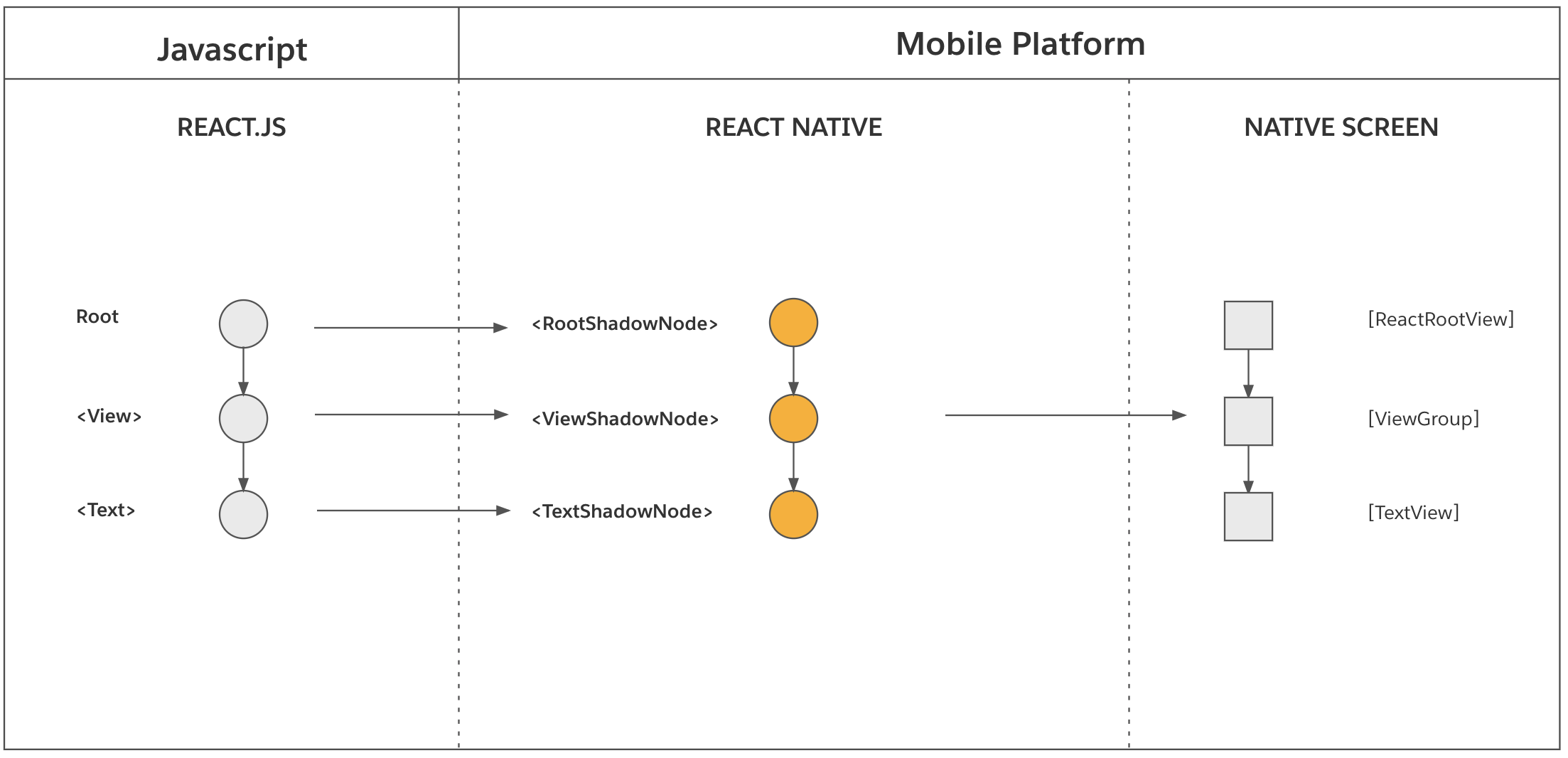
更详细地说,挂载阶段由三个步骤组成:
- 树对比(Tree Diffing): 这个步骤完全用的是 C++ 计算的,会对比“已经渲染的树”(previously rendered tree)和”下一棵树”之间的差异。计算的结果是一系列宿主平台上的原子变更操作,比如
createView,updateView,removeView,deleteView等等。在这个步骤中,还会将 React 影子树拍平,来避免不必要的宿主视图创建。关于视图拍平的算法细节可以在后文找到。 - **树提升,从下一棵树到已渲染树(Tree Promotion,Next Tree → Rendered Tree):**在这个步骤中,会自动将“下一棵树”提升为“先前渲染的树”,因此在下一个挂载阶段,树的对比计算用的是正确的树。
- **视图挂载(View Mounting):**这个步骤会在对应的原生视图上执行原子变更操作,该步骤是发生在原生平台的 UI 线程的。
更多细节
- 挂载阶段的所有操作都是在 UI 线程同步执行的。如果提交阶段是在后台线程执行,那么在挂载阶段会在 UI 线程的下一个“tick”执行。另外,如果提交阶段是在 UI 线程执行的,那么挂载阶段也是在 UI 线程执行。
- 挂载阶段的调度和执行很大程度取决于宿主平台。例如,当前 Android 和 iOS 挂载层的渲染架构是不一样的。
- 在初始化渲染时,“先前渲染的树”是空的。因此,树对比(tree diffing)步骤只会生成一系列仅包含创建视图、设置属性、添加视图的变更操作。而在接下来的 React 状态更新场景中,树对比的性能至关重要。
- 在当前生产环境的测试中,在视图拍平之前,React 影子树通常由大约 600-1000 个 React 影子节点组成。在视图拍平之后,树的节点数量会减少到大约 200 个。在 iPad 或桌面应用程序上,这个节点数量可能要乘个 10。
React 状态更新
接下来,我们继续看 React 状态更新时,渲染流水线(render pipeline)的各个阶段是什么样的。假设你在初始化渲染时,渲染的是如下组件:
function MyComponent() {
return (
<View>
<View
style={{backgroundColor: 'red', height: 20, width: 20}}
/>
<View
style={{backgroundColor: 'blue', height: 20, width: 20}}
/>
</View>
);
}
应用我们在初次渲染部分学的知识,你可以得到如下的三棵树:
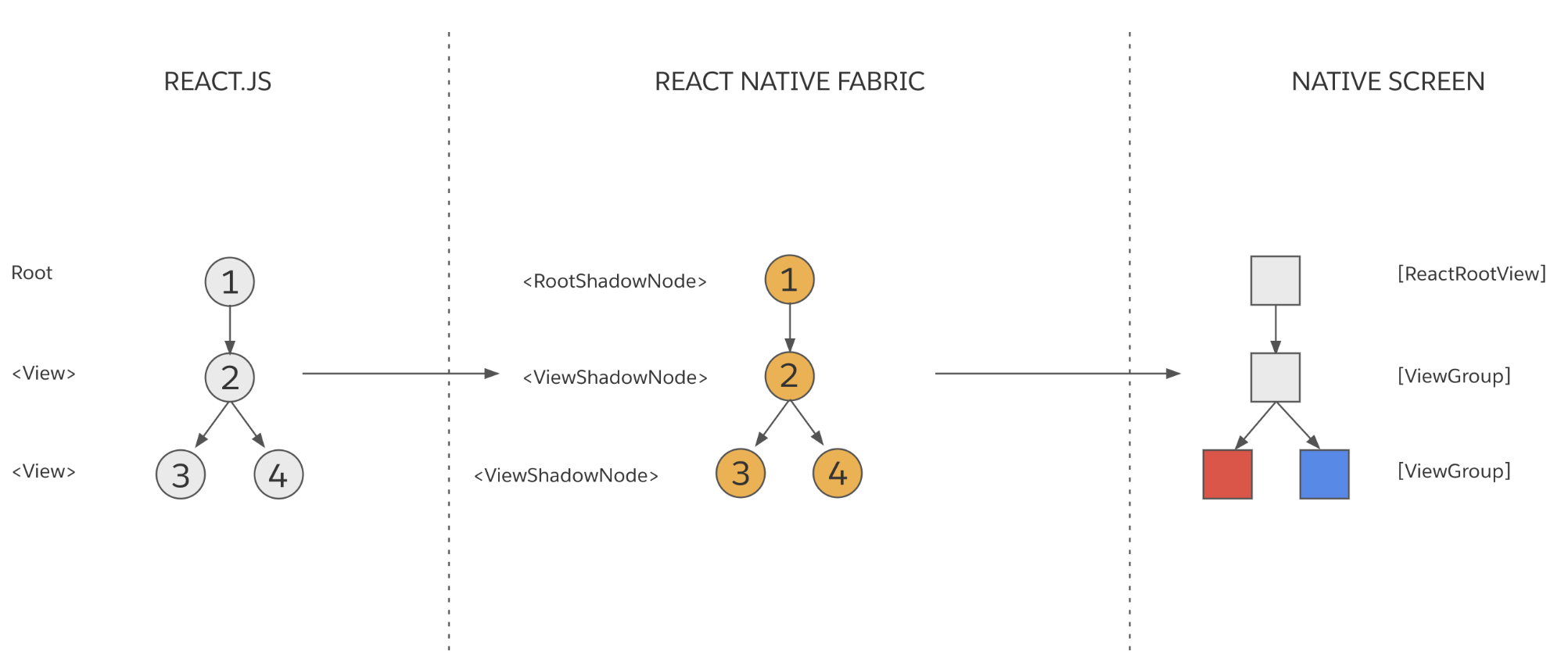
请注意,节点 3 对应的宿主视图背景是红的,而节点 4 对应的宿主视图背景是蓝的。假设 JavaScript 的产品逻辑是,将第一个内嵌的<View>的背景颜色由红色改为黄色。新的 React 元素树看起来大概是这样:
<View>
<View
style={{backgroundColor: 'yellow', height: 20, width: 20}}
/>
<View
style={{backgroundColor: 'blue', height: 20, width: 20}}
/>
</View>
React Native 是如何处理这个更新的?
从概念上讲,当发生状态更新时,为了更新已经挂载的宿主视图,渲染器需要直接更新 React 元素树。 但是为了线程的安全,React 元素树和 React 影子树都必须是不可变的(immutable)。这意味着 React 并不能直接改变当前的 React 元素树和 React 影子树,而是必须为每棵树创建一个包含新属性、新样式和新子节点的新副本。
让我们继续探究状态更新时,渲染流水线的各个阶段发生了什么。
阶段一:渲染
React 要创建了一个包含新状态的新的 React 元素树,它就要复制所有变更的 React 元素和 React 影子节点。 复制后,再提交新的 React 元素树。
React Native 渲染器利用结构共享的方式,将不可变特性的开销变得最小。为了更新 React 元素的新状态,从该元素到根元素路径上的所有元素都需要复制。 但 React 只会复制有新属性、新样式或新子元素的 React 元素,任何没有因状态更新发生变动的 React 元素都不会复制,而是由新树和旧树共享。
在上面的例子中,React 创建新树使用了这些操作:
- CloneNode(Node 3,
{backgroundColor: 'yellow'}) → Node 3' - CloneNode(Node 2) → Node 2'
- AppendChild(Node 2', Node 3')
- AppendChild(Node 2', Node 4)
- CloneNode(Node 1) → Node 1'
- AppendChild(Node 1', Node 2')
操作完成后,**节点 1'(Node 1')**就是新的 React 元素树的根节点。我们用 T 代表“先前渲染的树”,用 T' 代表“新树”。
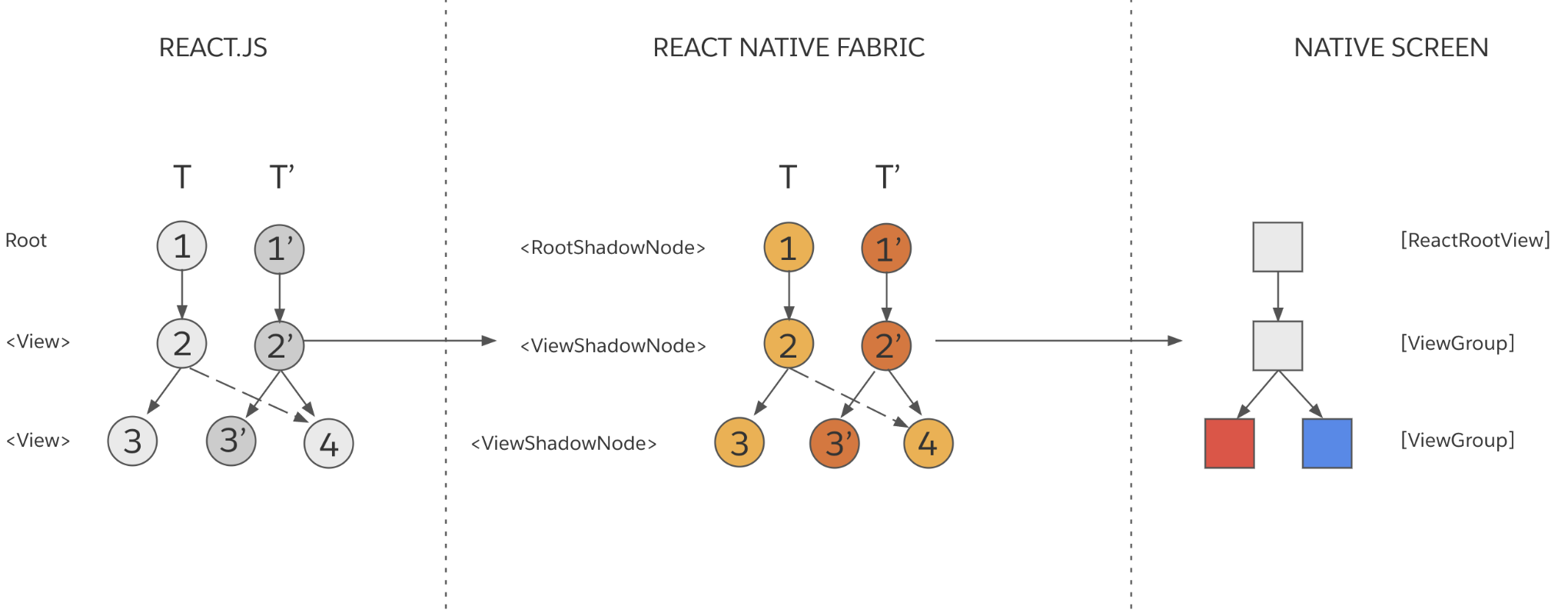
注意节点 4 在 T and T' 之间是共享的。结构共享提升了性能并减少了内存的使用。
阶段二:提交
在 React 创建完新的 React 元素树和 React 影子树后,需要提交它们。
- **布局计算(Layout Calculation):**状态更新时的布局计算,和初始化渲染的布局计算类似。一个重要的不同之处是布局计算可能会导致共享的 React 影子节点被复制。这是因为,如果共享的 React 影子节点的父节点引起了布局改变,共享的 React 影子节点的布局也可能发生改变。
- 树提升(Tree Promotion ,New Tree → Next Tree): 和初始化渲染的树提升类似。
- 树对比(Tree Diffing): 这个步骤会计算“先前渲染的树”(T)和“下一棵树”(T')的区别。计算的结果是原生视图的变更操作。
- 在上面的例子中,这些操作包括:
UpdateView(**Node 3'**, {backgroundColor: '“yellow“})
- 在上面的例子中,这些操作包括:
阶段三:挂载
- 树提升(Tree Promotion ,Next Tree → Rendered Tree): 在这个步骤中,会自动将“下一棵树”提升为“先前渲染的树”,因此在下一个挂载阶段,树的对比计算用的是正确的树。
- **视图挂载(View Mounting):这个步骤会在对应的原生视图上执行原子变更操作。在上面的例子中,只有视图 3(View 3)**的背景颜色会更新,变为黄色。
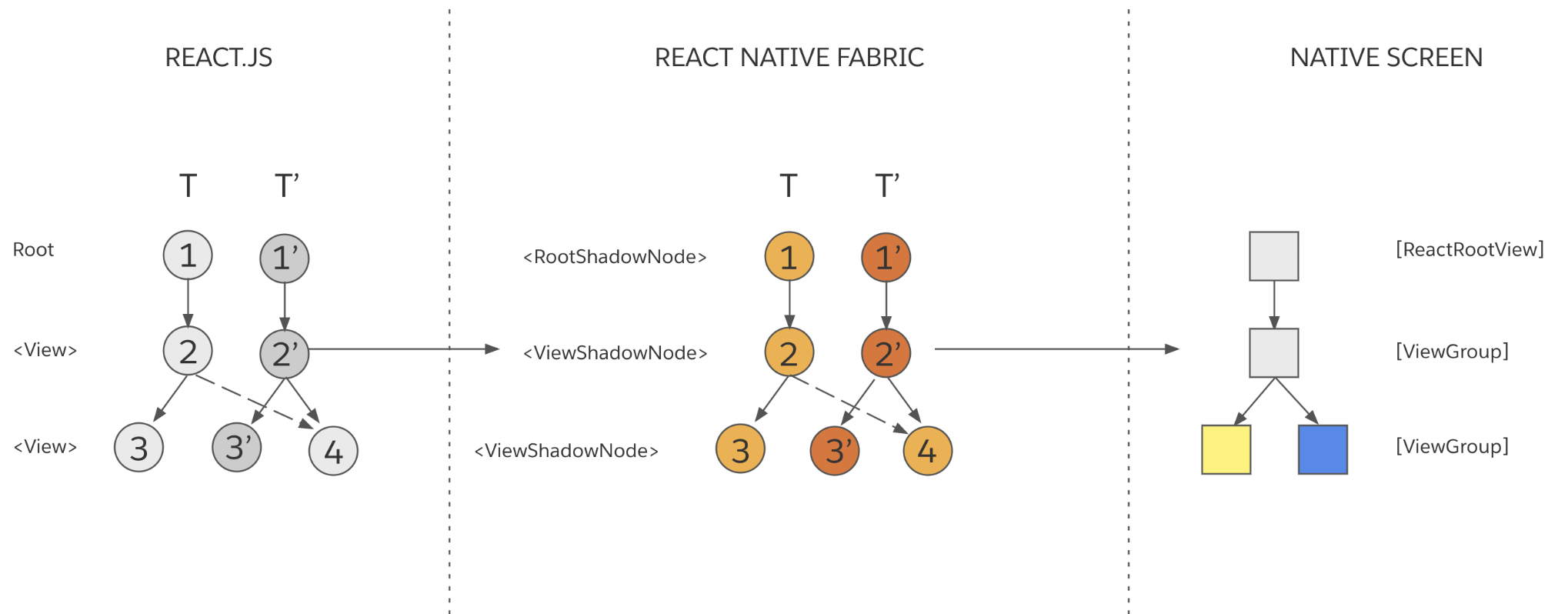
React Native 渲染器状态更新
对于影子树中的大多数信息而言,React 是唯一所有方也是唯一事实源。并且所有来源于 React 的数据都是单向流动的。
但有一个例外。这个例外是一种非常重要的机制:C++ 组件可以拥有状态,且该状态可以不直接暴露给 JavaScript,这时候 JavaScript (或 React)就不是唯一事实源了。通常,只有复杂的宿主组件才会用到 C++ 状态,绝大多数宿主组件都不需要此功能。
例如,ScrollView 使用这种机制让渲染器知道当前的偏移量是多少。偏移量的更新是宿主平台的触发,具体地说是 ScrollView 组件。这些偏移量信息在 React Native 的 measure 等 API 中有用到。 因为偏移量数据是由 C++ 状态持有的,所以源于宿主平台更新,不影响 React 元素树。
从概念上讲,C++ 状态更新类似于我们前面提到的 React 状态更新,但有两点不同:
- 因为不涉及 React,所以跳过了“渲染阶段”(Render phase)。
- 更新可以源自和发生在任何线程,包括主线程。
阶段二:提交
提交阶段(Commit Phase):在执行 C++ 状态更新时,会有一段代码把影子节点**(N)**的 C++ 状态设置为值 S。React Native 渲染器会反复尝试获取 N 的最新提交版本,并使用新状态 S 复制它 ,并将新的影子节点 N' 提交给影子树。如果 React 在此期间执行了另一次提交,或者其他 C++ 状态有了更新,本次 C++ 状态提交失败。这时渲染器将多次重试 C++ 状态更新,直到提交成功。这可以防止真实源的冲突和竞争。
阶段三:挂载
挂载阶段(Mount Phase)实际上与 React 状态更新的挂载阶段相同。渲染器仍然需要重新计算布局、执行树对比等操作。详细步骤在前面已经讲过了。